10 SaaS Knowledge Base Examples That Work in 2026



The best SaaS knowledge bases no longer function as static help centers. They power AI search, in-app support, conversational help, and faster self-service experiences.
That shift has made documentation quality far more important. Poor structure, outdated articles, and fragmented information now create worse support experiences for both users and AI systems pulling from your docs.
In this article, we’ll look at 10 SaaS knowledge base examples that reduce friction, what each one does particularly well, and the lessons you can apply to your own support experience.

Best SaaS knowledge base examples (and what to steal from each)
We picked these 10 SaaS knowledge base examples because each one solves support friction differently, whether through AI-powered search, contextual help, faster onboarding, or smarter self-service design.
1. Intercom: AI support that runs on documentation quality
Intercom’s Fin AI agent is the clearest real-world demonstration that knowledge base quality has become a business metric. Fin reads Articles, PDFs, and connected URLs, ingests them almost instantly, and uses that content to resolve conversations without human escalation. By December 2025, Fin had handled over 40 million conversations and maintained a 67% resolution rate.
The reason that resolution rate matters for your knowledge base is not benchmarking alone. Every percentage point Fin fails to resolve is, in many cases, a content failure rather than a model failure. Vague headings, buried answers, and outdated procedures translate directly into conversations that get escalated to a human agent.
Intercom’s own knowledge base reflects this: direct answers, specific headings and content organized by user task rather than feature category. It is built to be parsed by the same kind of agent that its customers run on top of it.
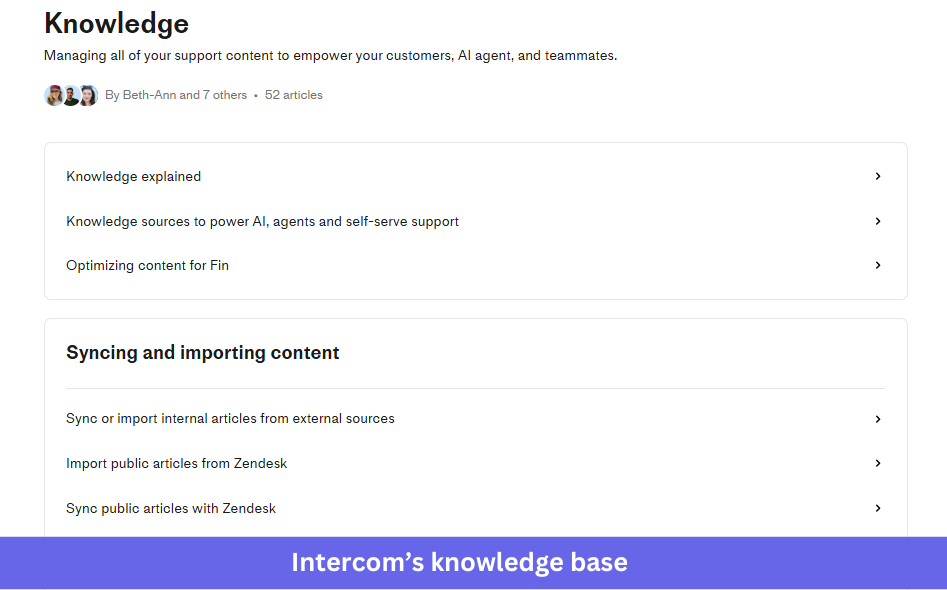
Lesson to learn: AI resolution rates are a lagging indicator of documentation quality. If your agent’s resolution rate is slipping, check your knowledge base before checking the model.
What to copy: Write every article heading as a specific task or question rather than a topic label. “How to reconnect a broken Slack integration” deflects a ticket. “Integrations” doesn’t.
2. Notion: Q&A agents running off your own documentation
With Custom Agents (version 3.3, February 2026), Notion turned its knowledge base into something closer to a 24/7 team member. The Q&A agent reads from a configured knowledge source, receives questions in Slack, and responds directly, without requiring anyone to open a browser or tag a colleague. Teams using it report handling internal policy lookups, onboarding questions, and recurring process questions that previously created ongoing Slack noise.
What’s instructive about the architecture is its constraint. The agent reads from a specific, curated knowledge source you define.
It doesn’t search the public internet. That means every answer it returns reflects exactly what you have put in the knowledge base, and every gap in your documentation becomes a gap in the agent’s answers.

Lesson to learn: An AI agent doesn’t flag when it’s working from outdated content. Every documentation gap becomes a wrong answer served at scale, silently, until someone notices the resolution rate slipping.
What to copy: Treat your knowledge base as infrastructure for AI agents, not only for human readers. Audit your most commonly queried topics first. Those are the articles your agent will draw from most often, and any errors in them compound at scale.
3. Asana: Multiple learning formats from one entry point
Asana’s in-app help center is built around the reality that users absorb information differently. From one widget, you can read an article, watch a video tutorial, take a self-paced course through Asana Academy, or register for live training. There’s no assumption that one format serves everyone.
Navigation is organized by user goal rather than product terminology, so a new user setting up their first project doesn’t need to know what Asana calls that workflow before finding help with it. For users who are new to both the product and its vocabulary, that’s a meaningful difference in how quickly they can move forward.
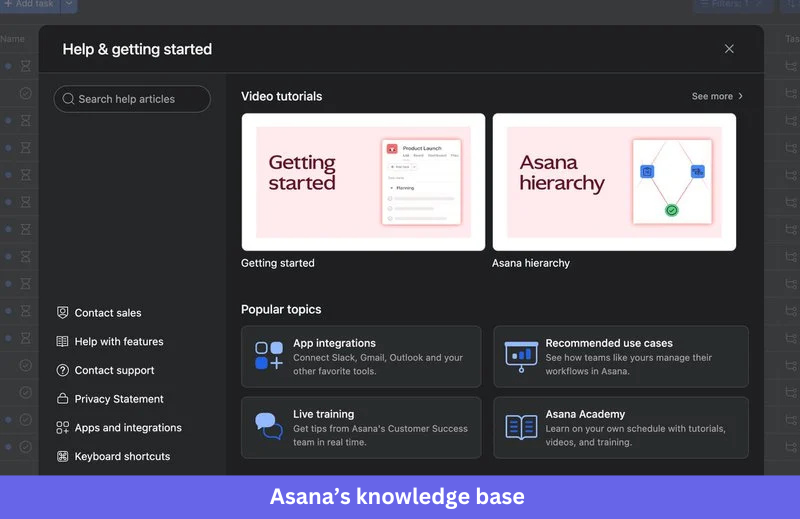
Lesson to learn: Format preference correlates with user type. The users who read articles and the users who watch videos are often meaningfully different people, with different learning preferences and different levels of product experience.
What to copy: For each of your core onboarding flows, offer at least two formats: a text article and a short video walkthrough. Most teams have one. Adding the second expands self-service reach without requiring you to rewrite anything.
4. Slack: Knowledge base as a feature communication surface
Slack treats its knowledge base as a product update surface, not a support archive. Slack surfaces new feature updates prominently inside its help center, helping users understand changes before confusion turns into support tickets.
The structure is built for momentum. Relevant content surfaces immediately, without requiring users to navigate category trees first. Popular topics appear pre-surfaced on the homepage, so users who aren’t sure what to search still find what they need without typing anything.
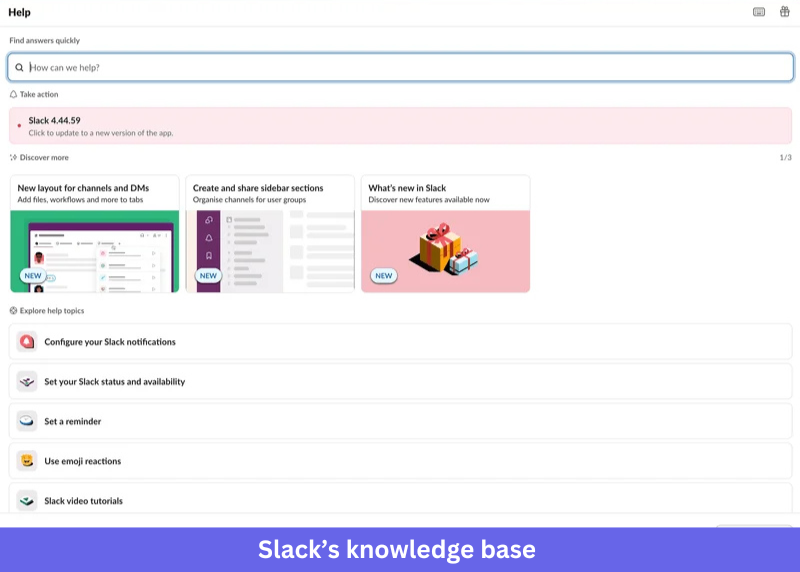
Lesson to learn: Users who open the help center immediately after a release are often confused by changes. Surfacing that explanation at the top of the homepage catches the confusion as it forms, before a ticket is filed.
What to copy: Put your three most recent feature updates at the top of your knowledge base homepage, refreshed with every release. Users shouldn’t have to navigate to a separate release notes page to understand why something looks different from last week.
5. Figma: Built for users who already know the product
Figma ships frequently, and most of its users are experienced enough to notice when something changes. The knowledge base reflects that assumption: video-first education and product launch content appear at the top, giving returning users a direct path to “what changed and why” without navigating through onboarding material they already covered.
Topics are grouped by workflow areas like components, typography, and prototyping instead of feature names. This helps users browse based on the task they’re working on. Power users often know the outcome they want, even if they don’t remember the exact name of the feature behind it.

Lesson to learn: Onboarding-first knowledge base design frustrates experienced users. If most of your active users have been in the product for more than three months, your homepage should reflect what they return for.
What to copy: Maintain a “What’s new” section updated with every release, keeping the last three feature releases visible at a glance. Users who return after time away will check this before anything else, so give them a clean path rather than leaving them to discover changes through errors.
6. Miro: Visual consistency between product and help content
Miro’s Learning Center is designed to feel like part of the product rather than a separate support site. Every tutorial uses custom illustrations that match the product’s visual language, and the overall design is clean enough that browsing help content feels consistent with using Miro itself.
That reduces the cognitive shift between product and documentation, which makes users more likely to complete a tutorial rather than abandoning it midway.
Interactive tutorials are one of Miro’s strongest onboarding elements. Instead of explaining how to create a board, Miro guides users through the process inside an embedded example. This helps users learn by doing and makes it easier to apply the skill later in the product.
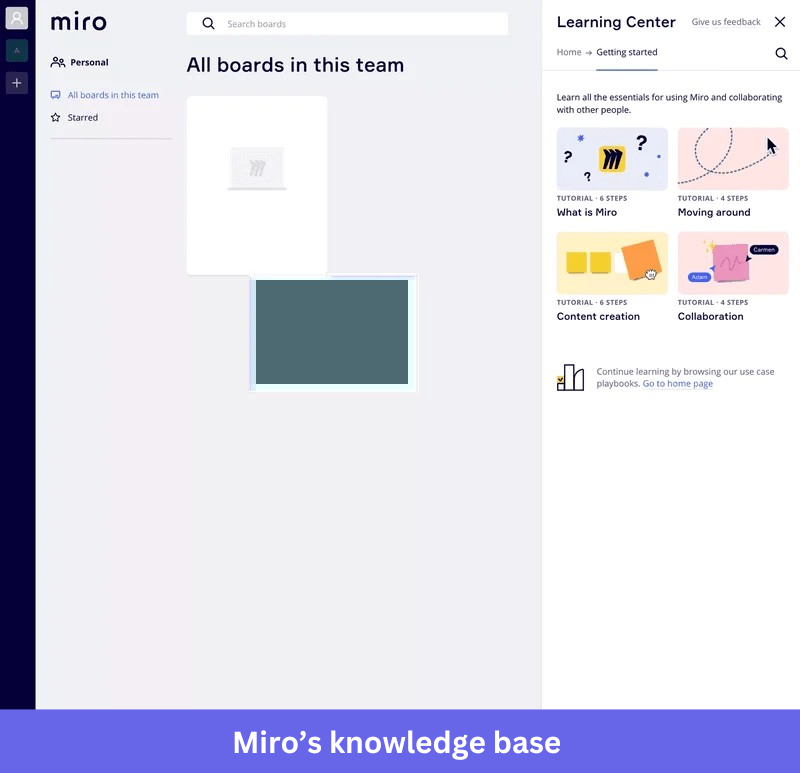
Lesson to learn: Visual consistency between your product and its help content lowers the psychological cost of asking for help. Users who feel they’ve left the product are less likely to engage with what they find on the other side.
What to copy: Use your product’s design system in your knowledge base screenshots and illustrations. Matching fonts, colors, and UI style makes the transition from product to help feel like a single experience rather than a detour to a different website.
7. Surfer: Community knowledge alongside official documentation
Surfer’s help center embeds an “Ask the community” option directly alongside the official search bar, giving users a second path to answers for questions that don’t appear in official documentation. That community layer crowdsources answers to niche edge cases your team hasn’t written articles for, while simultaneously surfacing which questions are common enough to warrant a dedicated page.
An AI-powered support interface handles conversational queries before routing to articles, and the quick-start material is prominent for new users without requiring experienced users to navigate past it every time they open help.
Lesson to learn: The highest-value knowledge base content often comes from power users solving edge cases your team hasn’t documented yet. That knowledge gets created regardless of whether you capture it in a structured, searchable place.
What to copy: Add a community forum or Q&A layer to your knowledge base. User-generated answers become searchable and citable content your AI agent can draw from when they exist in a structured location. Left in scattered support threads, they help no one twice.
8. Loom: Video-first help from a video product
Loom’s knowledge base does what you’d expect from a company whose product is video: it surfaces video content immediately, makes it the easiest format to find, and organizes everything around visual formats first. The help center opens from inside the app, so support is always one click away from wherever a user is in the product.
Large topic tiles (Recording and Editing, Security, Use Cases) give users an immediate overview of what the knowledge base covers. Popular questions appear on the homepage without requiring any search input, which means users with the most common needs don’t have to type anything at all.

Lesson to learn: The format your product centers on should also be the format your knowledge base leads with. Users who chose your product for its video capabilities will expect that same emphasis in your help experience.
What to copy: Pre-surface the five most common questions on your knowledge base homepage without requiring any search input. Users with the most frequently asked questions shouldn’t have to type anything. They should see the answer path the moment they open the help center.
9. Jira: Technical depth for specific error-state problems
Jira’s knowledge base is designed to help users troubleshoot specific technical issues, such as proxy configuration, SQL errors, or plugin upload failures. The documentation remains detailed without being difficult to navigate, and users can turn to the Atlassian community when they need help beyond the official guides. Articles are concise and technical, without unnecessary introductions.
Search works well for highly specific queries. Exact error codes surface the right article quickly instead of returning loosely related results. Recent updates also appear directly on the homepage, so users can track changes without checking a separate release notes section.
Via Jira. Recent updates at the top tell developers what changed without requiring a separate release notes tab.
Lesson to learn: Technical users searching for error codes and API responses need exact-match results, not thematically related articles. General-purpose search tuning often fails this use case, and developers notice immediately.
What to copy: If your product serves developers, tag your articles with exact error codes, API response strings, and CLI command outputs. A developer searching for a specific error string needs that article to surface first, not after five results that broadly relate to the problem but don’t address it.
10. Zoom: Clean organization at genuinely difficult scale
Zoom’s knowledge base handles a legitimately hard constraint: a massive user base spanning admins, hosts, and participants across meetings, webinars, phone, and AI Companion. The solution is clean categorization by task and role (audio troubleshooting, account setup, AI features), so different user types can navigate directly to their context without first filtering through irrelevant content.
The homepage stays organized despite covering enormous ground. Release notes, training resources, and popular articles are all present, well-structured, and easy to find. For teams with multiple user roles and different support needs, Zoom is a strong example of handling complexity without turning the homepage into a content dump.
Lesson to learn: When your product serves multiple user roles with different support needs, a single homepage trying to serve all of them typically serves none of them well. Role-based entry points reduce friction without requiring separate knowledge bases.
What to copy: If your product has distinct user roles (admins, end users, developers), create separate entry points or filtered views in your knowledge base. A first-time admin setting up workspace permissions and a developer debugging an API integration should not navigate the same content hierarchy to find what they need.
What AI has changed about knowledge bases
In April 2026, Andrej Karpathy published a workflow for building and maintaining a structured markdown knowledge base entirely with LLMs, without vector databases. The project reached 16 million views and more than 5,000 GitHub stars in its first weeks. The core concept: an LLM builds and updates a structured markdown KB from raw sources, and AI agents navigate it without needing embeddings or retrieval infrastructure. The full breakdown is at blog.starmorph.com.
Most teams aren’t building this yet. But the signal matters: the knowledge base is shifting from something a team maintains manually to infrastructure that AI increasingly helps write, organize, and navigate. Even if you’re nowhere near that stage, three things have already changed for every team running a knowledge base in 2026.
1. The dual-reader problem
Your knowledge base now has two audiences. Human users read it, interpret the context, fill in gaps, and adjust when something seems off. AI agents read it literally, return answers based on what the text says, and have no mechanism for detecting when an article is six months out of date.
A vague heading or stale procedure causes your AI support agent to return a confident, wrong answer with no error state, no visible alert, and no signal that anything went wrong. The only indicator is a slightly lower resolution rate on a dashboard that most teams check at best weekly.
Writing for human readers remains necessary, but the standards for AI agents differ enough to warrant separate consideration when auditing or creating content.
A few practices that help: write every article heading as a specific task or question rather than a category label. Put the direct answer in the first sentence rather than building up to it. Lastly, test your AI agent against your five most-searched topics to see what it actually returns. If the answers are vague or incomplete, the fix is almost always in the article structure, not the model.
2. AI now writes articles
Platforms like Pylon and Zendesk can auto-draft knowledge base articles from resolved support tickets. A ticket gets closed, the resolution is captured, and a draft article appears in the queue for a human to review and publish. Teams using this workflow have cut the time between identifying a documentation gap and filling it from weeks to days.
The deflection numbers reflect this. Traditional self-service knowledge bases deflect 15-25% of tickets, according to data from omq.ai.
Teams with AI-powered search, chatbot integration, and automated article creation hit 40 to 60 percent. The gap is primarily about documentation coverage and freshness, not volume.
AI-assisted drafting doesn’t replace editorial judgment. It removes the blank-page problem and the backlog of “we should document this” items that never get written because no one has time to start from scratch.
A practical way to start: set up a weekly review queue that surfaces resolved tickets from the past seven days as draft article candidates. And assign one person to review and publish on a rolling basis rather than scheduling a quarterly documentation sprint that never quite happens.
3. AI detects what’s missing
Failed searches have always been the clearest signal that a knowledge base has gaps. Most teams either didn’t track them or reviewed them too infrequently to act. Modern platforms now analyze failed searches, unresolved AI agent conversations, and repeated ticket patterns to flag content gaps automatically and surface them in a dashboard.
This changes knowledge base maintenance from a periodic audit into a continuous feedback loop. A new feature ships, users encounter a specific edge case, failed searches accumulate, and the platform surfaces that topic as a gap before anyone files a formal ticket. The team can write the article before the problem compounds across a user segment.
Three signals worth tracking: a failed search rate above 15% (each failed query is a documented gap), unresolved AI agent conversations where the agent escalated or returned a low-confidence answer, and repeated tickets on the same topic within a two-week window.
Any of these appearing consistently points to a content gap worth addressing before it starts driving volume. A self-service knowledge base platform with built-in gap detection will surface these automatically.
Build a knowledge base people actually use
The pattern across every example above comes back to the same two audiences. Human users need to find answers without friction. AI agents need to parse the same content and return accurate results.
A knowledge base that serves one audience well while failing the other will show up in resolution rates, ticket volume, or both.
The gap between deflecting 60 percent of tickets and 20 percent is almost never due to content volume. It comes down to structure, delivery mechanism, and whether the content is maintained actively enough to stay accurate as the product changes.
If you want to build an in-app resource center that works for both audiences without engineering involvement, get started with Userpilot or book a demo to see how other product-led teams have set it up.
FAQ
What is a knowledge base for SaaS?
A SaaS knowledge base is a centralized platform that lets users find answers to their questions, learn how to use product features, and troubleshoot issues without contacting your support team. In 2026, a knowledge base also serves as the content layer that AI support agents read to generate answers. That makes content quality and article structure more consequential than ever, because poorly written docs produce poor AI answers in addition to poor user experiences.
What is the best knowledge base software for SaaS?
The right choice depends on your use case. If your priority is an in-app knowledge base that reduces support tickets and surfaces help contextually, Userpilot is the top pick for product-led teams. You can build searchable help content, target it by user segment, and trigger tooltips and walkthroughs, all without engineering effort.
Document360 is the strongest option for teams that need a standalone documentation site with version control and complex content hierarchies. Gleap is worth evaluating if you want AI-powered search and all-in-one support tooling in a single platform.
About the author




