How I’d Run a Product Pilot Today



A lot of teams misunderstand what a pilot is supposed to do. The goal is not to prove the product works but to find out whether the product is worth scaling before you burn months rolling it out broadly.
It gets worse in this AI era because now it’s cheap to build polished-looking software, which means teams mistake “people were impressed in the demo” for validation. Meanwhile, buyers have gotten more skeptical, too. Most companies have already seen enough pilots that dragged on forever, turned into unpaid implementation work, or never made it past experimentation.
So the standard for a good pilot is much higher now. You need usage, behavior change, and proof that the product survives outside the excitement of trying something new.
That’s what I want to break down in this guide: how to run a pilot launch that reduces uncertainty.

Is there a real difference between a pilot, an MVP, and a beta?
But first, let’s get a few terms straight. Product pilots, MVPs, and betas are used interchangeably across most product teams, and the operational differences determine whether your pilot data is worth acting on.
What is a product pilot?
A product pilot is a closed, time-boxed release with a defined success criterion and a built-in off-ramp. You pick a select group of users, run the feature with them on a small scale for a defined period, measure against a hypothesis you set in advance, and make a decision: ship, kill, or redesign. The “product pilot” label gets applied to a lot of things it does not describe: soft launches, ongoing betas, features quietly rolled out to 10% of users for six months.
The desired outcome you define in advance is what gives the pilot its shape. Without a success criterion tied to a business metric, a pilot can run indefinitely and still produce no actionable decision. What a pilot is designed to validate should be on paper before the first participant joins, because the most important thing a pilot does is prevent a feature from becoming part of the final product before that question has a real answer.
Pilot vs MVP
An MVP tests whether demand exists; a pilot tests whether what you built works as intended. Minimum viable products go broad with a minimal version because you are solving for an on-demand signal. A pilot assumes demand is established and tests whether the built version delivers on that demand in a real-world context, with a smaller, more deliberate audience. Running a pilot on something where demand is still an open question is the wrong sequencing. You need the MVP answer first.
Pilot vs beta
A beta is open and, in practice, indefinite. It optimizes for volume of feedback from beta testers across a wider audience, often with no formal end date or conversion expectation. A pilot is closed, scoped, and ends when the criteria are met or the time limit runs out. The operational difference matters more than the naming: if a pilot participant does not know when the engagement ends or what success looks like, you have run a beta and called it a pilot. The off-ramp is what separates them from a public release.
The paid vs free debate
Whether to charge for a pilot depends on what stage you are in. I find Jon Schipp’s practitioner analysis the most useful framing in this case. Paid pilots work best at the late-beta stage, when usability data matters, but so does the signal that someone will actually pay.
If you’re still figuring out whether the problem is painful enough or whether your workflow even makes sense, free pilots are fine. At that stage, the speed of learning matters more than revenue because you’re buying feedback.
But once the product is reasonably usable, I think not charging becomes dangerous. Because the moment there’s no financial commitment, the customer stops prioritizing rollout, and suddenly you’re three months deep into what is basically unpaid implementation work.
I’ve seen a lot of founders mistake activity for validation there. “The customer is engaged” sounds good until you realize nobody is trying to buy.
Personally, I think every pilot should eventually have a pay-or-progress expectation attached, even if the amount is small. Not because the revenue itself matters, but because payment changes behavior. People are more likely to implement, give honest feedback, and make internal decisions instead of treating the pilot like an endless experiment that they can abandon at any point.
Who should you run the pilot with?
The best pilot customers are usually operators with an active problem and enough influence to do something about it. They don’t need to be sold on why the category matters because they already live the problem every day.
Because honestly, nobody cares that you built a new tool. Especially in B2B. People are busy, they already get spammed constantly, and “free pilot” by itself is not compelling anymore.
What works better is showing that you looked at their situation. So instead of messaging twenty firms saying “I built an accounting automation platform,” I’d rather message five firms and say something specific like: “I noticed your team is still doing X manually,” or “most firms your size lose a lot of time on Y during month-end close.”
For the same reason, I think communities work better than cold outbound for first pilots. Not because communities magically convert better, but because people can see you repeatedly talking about the problem, and they are in the discussion because they already care.
How to identify the right participants?
What I find helpful is to stop thinking of landing pilot users as a launch activity and think of it as curated recruiting. You are looking for a specific operational profile, and volume works against you. Segmenting existing users by their jobs-to-be-done and past engagement patterns, and looking for behavioral evidence of the problem rather than demographic fit, is how you surface that profile at scale. Defining your Ideal Customer Profile (ICP) before you start recruiting saves the time most teams spend backfilling after weak pilots.
In Notion’s case, they rolled out Sprint Planning features within Notion Projects, with access limited to users already working in structured project-management templates and workflows. The pilot was not trying to convince random users to adopt sprint planning. It was testing whether teams already operating that way would consolidate the workflow into Notion itself.

I also think distribution has changed a lot for early-stage pilots. Ten years ago, founders mostly relied on outbound. Now, a lot of startup founders are basically building in public and using LinkedIn as the testing ground.
If you already have an audience, even a small one, use it.
Not in the “buy my product” way, but in the “here’s a problem I keep seeing” way. Because that does two things at once. It attracts potential pilot users, and it pre-educates them before you ever reach out directly.
I’ve seen founders post a rough prototype, talk openly about what they’re trying to automate, share screenshots of the workflow, and get pilot customers straight from the comments or DMs.
Where else can you find pilot partners?
Warm intros remain the highest-converting acquisition channel for pilot participants, and nothing has replaced them. For the channels that complement them, job board monitoring is the most underreported: monitor for companies posting roles that signal your problem and reach out that same week.
Multiple practitioners report three of their first five pilots coming from this approach, because a job posting is a live signal of felt pain and budget intention in a way that a LinkedIn search is not.
Niche community presence works best in trust-slow verticals like accounting, legal, and healthcare, where product leaders and operators help each other before they recommend solutions.
Show up with genuine value in sector-specific Slack groups or forums before you mention what you are building. Problem-evidence outreach is the tactic with the most notably higher response rates: find a publicly observable pain signal on the prospect’s business and open with that specific observation, rather than a free-trial pitch for a new solution they have no reason to trust yet.
How do you structure a pilot?
First, define one thing the pilot is supposed to prove.
Then I’d lock four things before the pilot even starts:
- What success looks like.
- How long the pilot lasts.
- Who owns the rollout internally.
- What happens after the pilot if it works.
I also strongly believe pilots should stay narrow. One workflow, one team, one use case. Founders get excited and try to prove the whole platform at once, then suddenly they’re doing custom integrations, edge-case requests, and basically acting like an agency.
Define the end-state in the first conversation
The first step in structuring a pilot program is getting this conversation on the table before either side invests: will they commit time, will they get value, will they pay, or will they refer? Most teams optimize for the first, getting a “yes” to participation, and defer the third until the pilot is well underway, when both sides have invested and walking away is psychologically harder.
That is the wrong order. Laying out the off-ramps in the first conversation filters out participants who were never going to convert, regardless of whether either side invests meaningfully.
Define success criteria explicitly and get the key questions on the table early: Is this a six-week engagement? What does a successful pilot look like at the end? Does it auto-convert to a paid plan, or is there a defined decision point? Getting those answers before anyone joins is not aggressive; it is how both sides avoid wasting time on a clear hypothesis that was never tested.
Scope it like a contract
I’d keep pilots short. Usually, 4–8 weeks is enough. Long pilots are usually a bad sign because it means nobody urgently needs the product when urgency creates movement.
The success metric should be tied to something the business already tracks. “30% faster risk review” is a usable pilot metric; “general improvement in efficiency” is not, because it cannot be falsified.
You should also include a defined change-request process. The change-request pricing exists not because clients are bad actors, but because scope expansion is a structural tendency in any engaged B2B relationship.
For example, a startup that landed a paid pilot with a large pharma company watched the scope expand into months of custom development, and got ghosted when the contract period ended. A locked scope document and a price list for anything outside the agreed spec are not paperwork overhead. They are what keep a pilot project from becoming a large investment with no deliverables and no off-ramp.
Use milestone-based payments for paid pilots
A 40/40/20 structure (40% at kickoff, 40% after user acceptance testing, 20% on measurable results) is a payment structure that I know works well for keeping both parties accountable.
It prevents the dynamic where the vendor delivers the full engagement on credit and then has no leverage if the client goes quiet. I also find the UAT milestone particularly useful as it creates a natural checkpoint where both sides confirm the product is functioning before the final 20% becomes contingent on outcomes, aligning customer value delivered with payment.
The value proposition of milestone payments goes beyond cash flow. Structuring payments around defined outcomes creates a shared incentive for both sides to engage genuinely at each checkpoint, which is what a well-run pilot needs to produce data worth acting on.

Write kill criteria into the agreement
I think every pilot should end with a real decision meeting. Not “let’s stay in touch.” An actual conversation where both sides look at the agreed metrics and decide: expand, pay, redesign, or stop. Otherwise, pilots become this weird permanent middle state where everyone sounds positive, but nobody is buying.
You can tell when the company has already mentally committed to launching, no matter what the pilot says. At that point, the pilot stops being a test and becomes a delayed rollout plan. Nobody is evaluating whether the product should move forward.
That’s why I think every pilot needs a defined failure condition upfront. What result would make both sides say, “This is not working yet”? What metric matters? Over what timeframe? And what happens if the pilot misses it?
Because if the pilot cannot produce a “stop and redesign” outcome, then you are not validating anything.
What should you track during a pilot?
I think founders track way too many things during pilots when the point is only to figure out one very simple thing: are people changing their behavior because of this product?
So I’d focus on four categories.
Track time-to-value
First, track time-to-value, not just completion rates. Because getting someone to finish the workflow is not the hard part, the question is whether they see the value fast enough to want to come back. Reducing time-to-value from three days to under one hour can have a measurable impact on pilot-to-retention conversion.
That’s why I care a lot about how quickly users reach the moment where the product becomes useful in their day-to-day work.
Funnel analysis can help you with this because you can see exactly where momentum drops in the workflow.
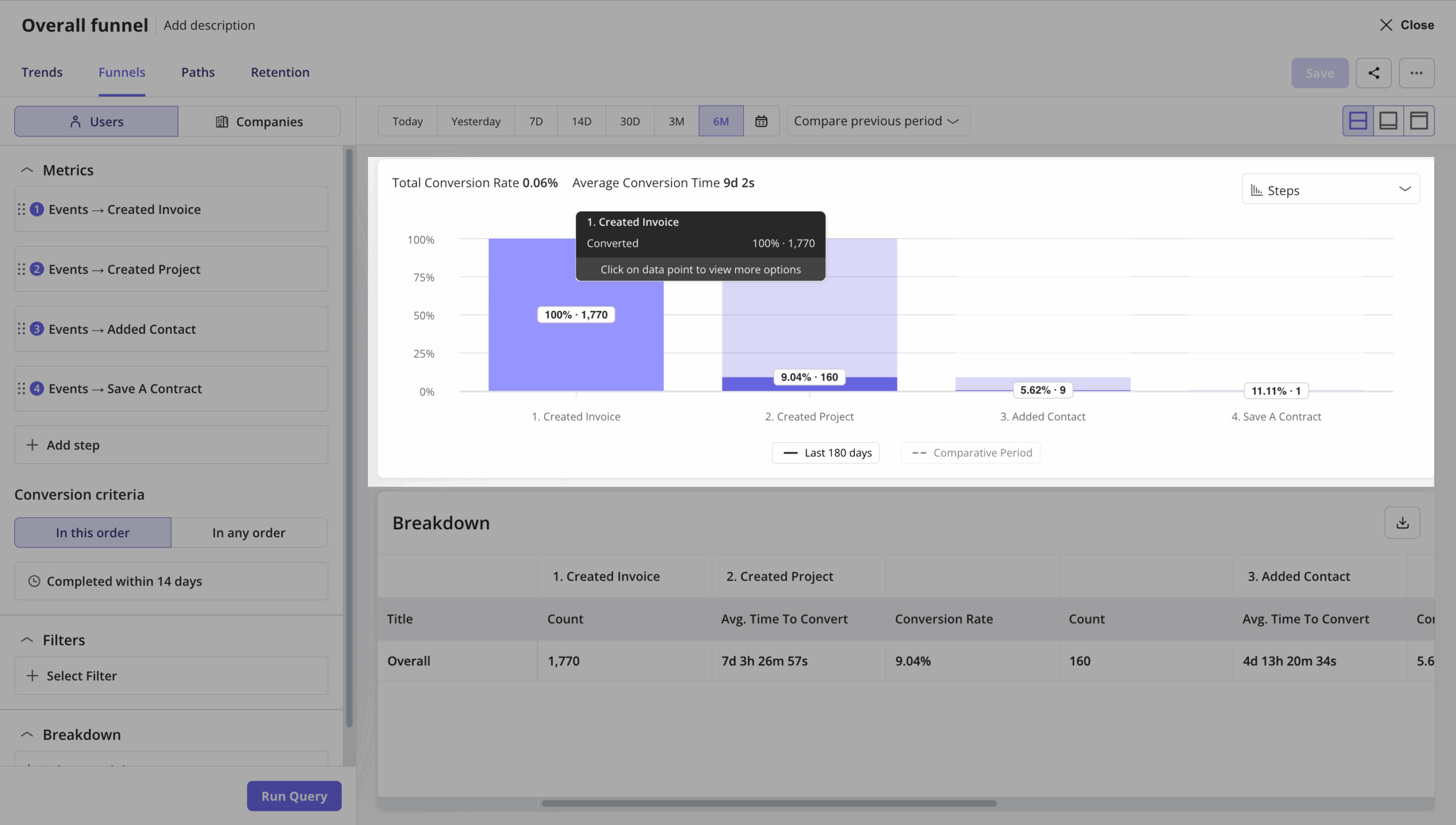
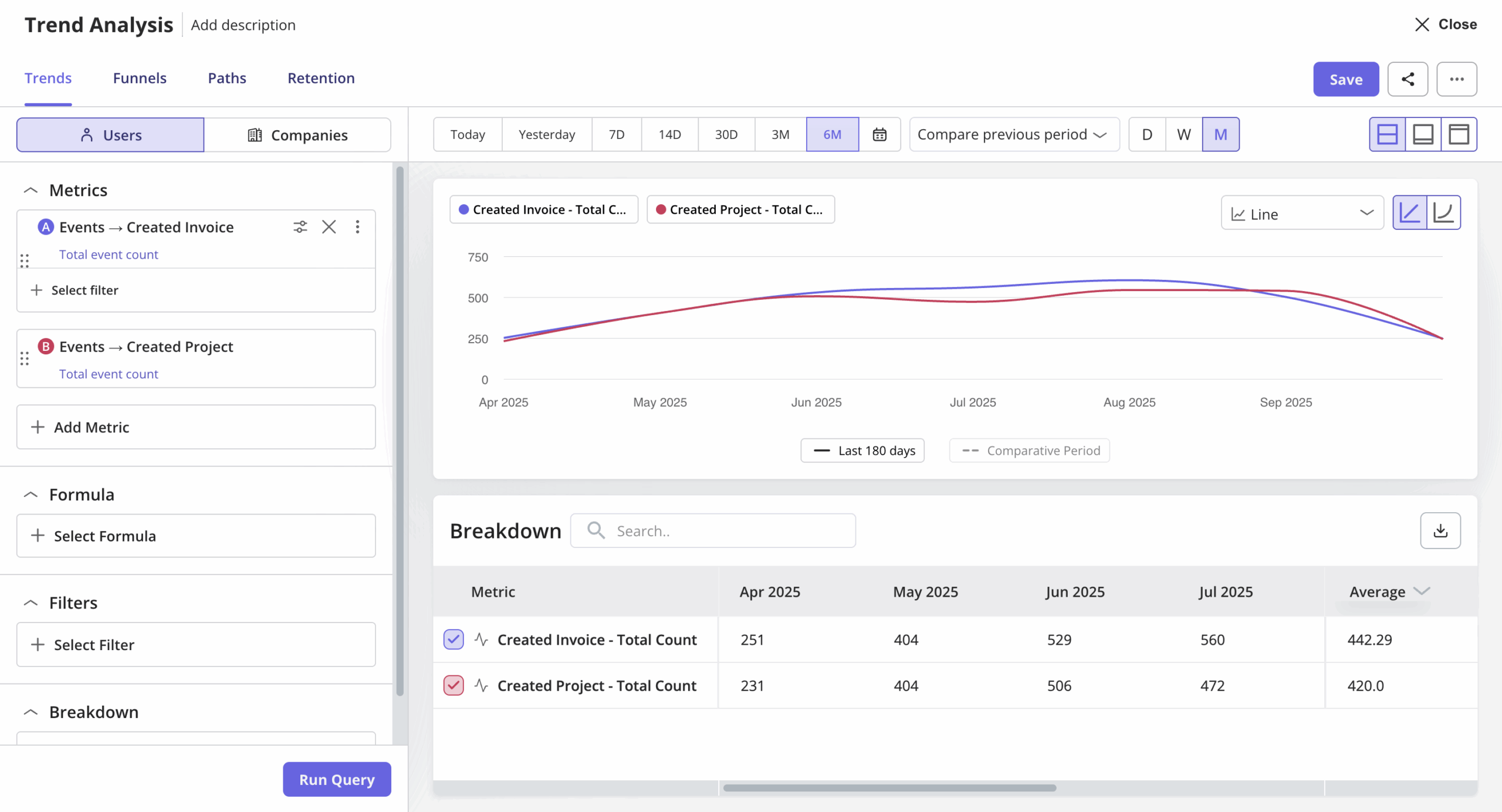
I’d also watch engagement trends across the pilot itself.
If usage keeps increasing over time, that usually means the product is becoming part of the workflow. If engagement spikes in week one and steadily declines after that, the product is probably generating curiosity more than habit.
That pattern tells you far more than a completion metric alone.
Run a mid-pilot survey by week four
One thing I’d do during the middle of the pilot is ask users a very simple open-ended question: “How would you describe this product to a colleague?”
Because by week four, the way users naturally explain the product tends to be more accurate than whatever is written on the landing page.
You start seeing whether users understand the product the way you intended, whether they associate it with the right problem, and whether the value proposition is landing clearly enough to repeat to someone else. That’s positioning data.
It’s much more useful to ask this mid-pilot instead of waiting until the end. End-of-pilot surveys tend to turn into retrospective summaries. People start rationalizing the experience instead of describing how they were using the product in the moment.
That’s also when I’d look at things like satisfaction trends, feature requests across accounts, and recurring friction points in the workflow. Not every feature request matters, but when multiple users independently describe the same missing step or workaround, that means the workflow still has structural friction.
Segment by activation patterns in the first two weeks
One thing worth paying attention to during pilots is which users become successful the fastest, and what they did differently in the first few sessions.
In my experience, a lot of the difference comes down to early behavior patterns.
Which features did they touch first? Which workflows did they complete on their own? Where did they hesitate? What steps did they skip entirely?
Once you start looking at pilots this way, you realize the goal is identifying the sequence of behaviors that predicts adoption.
For example, if we ship something, the first thing I do is build a report around the events that represent the feature being used. It can be a process or a few events completed together. Then I watch where the drop-off is happening and which step users are getting stuck on. If two accounts in a five-account pilot show the same drop-off in the same step, that workflow is telling you something.
This is also where I lean on Lia, our AI agent inside Userpilot. Lia monitors the metrics you care about and flags anomalies as they happen, so I’m not waiting until the end-of-pilot review to notice that one cohort stalled in week two. She’ll surface the drop-off, give the reasoning behind it, and recommend what to look at next, which compresses what used to be a manual weekly dig into something I can act on the same day.
Design the pilot-to-case-study pipeline from day one
I think founders underestimate how much the first successful pilot shapes the next ten sales conversations.
Because the output of a pilot is not the feature iteration but the reference customer, the internal success story, and the language users use to describe the product afterward.
So at the start of the pilot, define what you want to capture. You can consider getting information such as:
- What changed operationally.
- What metric improved.
- How long implementation took.
- What resistance existed internally.
- What surprised the customer during rollout.
I’d also identify early who inside the customer account will become the internal champion for the case study. That person is often the best source for operational language, before-and-after comparisons, and referral introductions later on.
And don’t wait until the pilot finishes to ask whether the customer is open to being a reference account. You should bring that up early once the pilot starts going well, as part of the partnership expectation: “if this works, we’d love to turn this into a public success story together.”
How does piloting an AI feature work differently?
Piloting an AI feature is different in one specific way, in that the output isn’t the same every time. That breaks the measurement framework you’d use for any other feature.
MIT’s “GenAI Divide” report found that 95% of enterprise AI pilots do not scale, delivering little to no measurable P&L impact. The failure is rarely the model. It is the absence of a measurement plan built for features that do not produce consistent outputs.
A McKinsey controlled study of 40 product managers on gen-AI-assisted product development demonstrated that the right pilot design matters for getting a clean signal on AI tools, and that the wrong one produces results that do not generalize to production.
Here’s what I’d do differently:
- Track output quality separately from engagement: Engagement is a decent proxy when features are deterministic. With AI, a user opening the tool every day might be in there correcting outputs, re-prompting, or working around what the model gave them. Add a thumbs up/down or a one-line rating to every interaction and look at it next to your usage numbers. That’s exactly what ChatGPT often does, which is asking users to rate the output or pick a response that they’d prefer.
- Measure the correction rate: Every time a user edits the output, re-prompts, or gives up and does it manually, that’s a correction. A high correction rate means the AI is making the user do the work it was supposed to do. You can use session replay to catch this because users don’t consciously notice how often they’re cleaning up after the model.
- Put skeptics in the pilot group: The volunteers for AI feature pilots are your most patient users. They’ll tolerate inconsistency, while your median user won’t. Drop in a few people who’ve never asked for AI tooling, as their threshold for “this works” is much closer to production reality.
- Set up production monitoring before the pilot closes: A pilot has eyes on it; production doesn’t. If the monitoring isn’t in place before you distribute your product, you lose visibility the moment the audience grows.
All of this is also to account for the future where the user of your AI feature might not be a person anymore:
“In a couple of years, people won’t be using software the way they are today. The end users aren’t the users of your software anymore — they’re consumers of the outputs of the agents, and the agents can be ours, like Lia, or external third-party agents accessing the data through our MCP.” — Yazan, our CEO at Userpilot
If that’s where things are going, your pilot measurement has to track agent behavior the same way it tracks human behavior. Re-prompts, task abandonment, and output handoffs to another system, all of which are the new signals. And we’re building Lia for that future where measuring agent activity should be part of your product analytics practices.
What does a well-run first pilot compound into?
The pilot-to-case-study pipeline is a choice. Make it one from the start, and the second pilot is easier to land than the first. The third is easier than the second. That’s the compounding dynamic that makes investing in excellent first pilots, rather than numerous ones, the smarter allocation.
If you want to see how the measurement infrastructure works in practice, funnel analysis, mid-pilot surveys, session replay, and always-on monitoring after launch, book a demo, and we can walk through a setup built around your feature type.
About the author



